DL-卷积神经网络-手写数字识别
手写数字识别
通过 MNIST 数据集训练得到一个手写数字分类器。设计一个至少包含 2 个卷积层和池化层的卷积神经网络。卷积核的尺寸不小于 5*5,要求训后的得到的网络在测试集确率不低于 96%,并在网络中使用 dropout
导包
1 | import torch |
数据集处理
dsets.MNIST:- 这是 PyTorch 的
datasets模块中的 MNIST 数据集类。 root='./': 指定数据集下载到当前工作目录下。train=True: 表示加载训练集,如果设为False,则加载测试集。transform:用于对数据进行预处理的操作。在这里,transforms.Compose组合了两个预处理操作:transforms.ToTensor(): 将图像数据转换为 PyTorch 张量。transforms.Normalize([0.1307,], [0.3081,]): 对图像进行标准化,减去均值(0.1307)并除以标准差(0.3081)。
- 这是 PyTorch 的
DataLoader:DataLoader是 PyTorch 提供的用于加载数据的工具。dataset=train_data: 指定要加载的数据集,这里是训练集或测试集。batch_size=64: 指定每个批次的样本数量为 64。shuffle=True: 表示在每个 epoch 开始的时候,对数据进行洗牌,以增加模型的泛化性能。
- 数据加载器 (
train_loader和test_loader):train_loader和test_loader是通过DataLoader加载训练集和测试集的实例。- 它们可以在训练和测试过程中迭代,每次返回一个批次的图像和对应的标签。
1 | train_data = dsets.MNIST(root='./', train=True, transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.1307,], [0.3081,])]), download=True) |
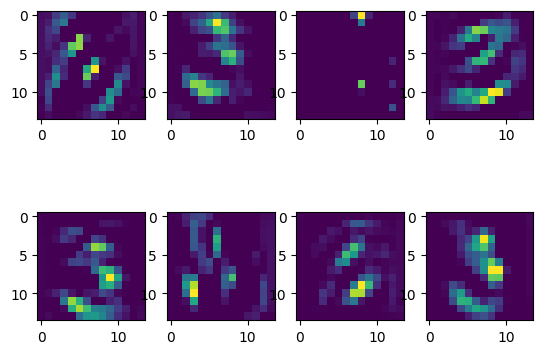
图片示例
train_data[50][0]: 获取该样本的特征,即图像数据。这里使用numpy()将 PyTorch 张量转换为 NumPy 数组。train_data[50][1]: 获取该样本的标签。img是 NumPy 数组,img[0, :]表示取图像的第一个通道(MNIST 数据集中是单通道灰度图像),但通过 viridis 颜色映射(colormap)呈现如下所示
1 | img = train_data[50][0].numpy() |
网络构建
初始化(
__init__方法):self.conv1: 第一个卷积层,输入通道数为1(灰度图像),输出通道数为4,卷积核大小为5x5,填充为2。self.pool: 最大池化层,窗口大小为2x2,步长为2。self.conv2: 第二个卷积层,输入通道数为4,输出通道数为8,卷积核大小为5x5,填充为2。self.fc1: 第一个全连接层,输入大小为(28*28)//(4*4)*8,输出大小为512。self.fc2: 第二个全连接层,输入大小为512,输出大小为10(对应10个类别)。
前向传播(
forward方法):- 接受输入
x,经过卷积层、激活函数(ReLU)、池化层、再经过卷积层、激活函数、池化层,然后将结果展平为一维张量。 - 经过第一个全连接层,再经过激活函数(ReLU)。
- 使用
F.dropout进行随机失活(dropout)操作,有助于防止过拟合。 - 最后经过第二个全连接层,输出最终的预测结果。
- 接受输入
特征图提取(
feature_maps方法):feature_maps方法用于提取输入图像经过第一个和第二个卷积层后的特征图。map1: 第一个卷积层后的特征图。map2: 第二个卷积层后的特征图。
Convolutional Layer (
nn.Conv2d(1, 4, 5, padding=2)):1: 输入通道数,表示输入图像的通道数,这里是灰度图像,所以通道数为1。4: 输出通道数,表示卷积核的数量,也就是这一层卷积操作会生成4个特征图。5: 卷积核的大小,5x5 的卷积核。padding=2: 填充操作,对输入图像的边缘进行零填充,保持特征图的大小不变。
Max Pooling Layer (
nn.MaxPool2d(2, 2)):2: 池化窗口大小,表示进行最大池化操作时,每个窗口的大小是2x2。2: 步长,表示在应用池化窗口时移动的步长,这里是2。
Fully Connected Layer (
nn.Linear((28*28)//(4*4)*8, 512)):输入大小:输入大小由最后一个卷积层的输出确定。在这种情况下,输入大小计算为
((28*28)//(4*4)*8),其中:28*28:输入图像的原始大小。//(4*4):通过两个最大池化层(窗口大小为2x2,步长为2)降低了空间维度,导致空间大小缩小了4倍。*8:来自最后一个卷积层的输出通道数。
输出大小:输出大小为
512,表示该层将产生一个 512 维的输出。
Dropout(
dropout(x, training=self.training)):在训练过程中对输入
x进行 dropout 操作。具体而言,它会随机将一部分输入元素设为零,以减少网络的过度拟合。在
self.training为True(即网络处于训练模式)时,F.dropout会执行 dropout 操作。而当self.training为False(即网络处于评估模式)时,F.dropout不会进行任何操作,保持输入不变。
- 输入图像通过
self.conv1卷积层后,生成4个特征图,然后通过self.pool池化层进行池化。 - 然后,通过
self.conv2卷积层,生成8个特征图,再次通过self.pool进行池化。 - 这样的结构允许网络逐渐学习和提取输入图像中的复杂特征,同时通过池化层减小特征图的空间尺寸,降低计算成本和参数数量。
- 网络末尾的全连接层将卷积层学到的高级特征转化为对分类任务每个类别的预测。
- 第一个全连接层 (
self.fc1) 负责将卷积层生成的具有空间排列的特征转换为一个平坦的向量。 - 第二个全连接层 (
self.fc2) 产生最终的输出,该层中的每个节点对应于输入属于特定类别的可能性(在这种情况下是0到9)。通常在此层之后应用 softmax 函数,将这些原始分数转换为概率。
1 | class Model(nn.Module): |
训练
net.train():与测试中net.eval()对应
momentum 是随机梯度下降(SGD)优化器的一个参数,控制了更新步骤中的动量项。
动量是一种在梯度下降中加速收敛的技术。在每个更新步骤中,动量项会考虑过去的梯度信息,以便在当前步骤中更好地指导参数的更新。momentum 参数表示动量项的权重,通常取值在 0 到 1 之间。
较大的动量值使得梯度更新在方向上更加平滑,有助于加速收敛,特别是在存在局部极小值或平坦区域的情况下。
1 | net = Model() |
测试
- Dropout层的影响:
- 在训练过程中,为了防止过拟合,通常会使用dropout层,在训练时以一定的概率将某些神经元置零。但在评估时,我们希望使用整个模型,而不是丢弃一些部分。因此,通过调用
net.eval(),dropout层会被设置为不激活,即所有神经元都参与运算。
- 在训练过程中,为了防止过拟合,通常会使用dropout层,在训练时以一定的概率将某些神经元置零。但在评估时,我们希望使用整个模型,而不是丢弃一些部分。因此,通过调用
- Batch Normalization层的影响:
- Batch Normalization(批标准化)在训练和评估时的计算方式不同。在训练时,Batch Normalization 使用每个mini-batch的均值和方差进行归一化。而在评估时,通常使用整个训练集的均值和方差进行归一化。通过
net.eval(),Batch Normalization层会使用评估时的统计信息。
- Batch Normalization(批标准化)在训练和评估时的计算方式不同。在训练时,Batch Normalization 使用每个mini-batch的均值和方差进行归一化。而在评估时,通常使用整个训练集的均值和方差进行归一化。通过
1 | def rightness(_pred, _y): |
准确率:
tensor(9904) 10000 tensor(0.9904)
输出特征图和卷积核
1 | plt.figure(figsize=(10, 8)) |
卷积核与特征图:
卷积核:
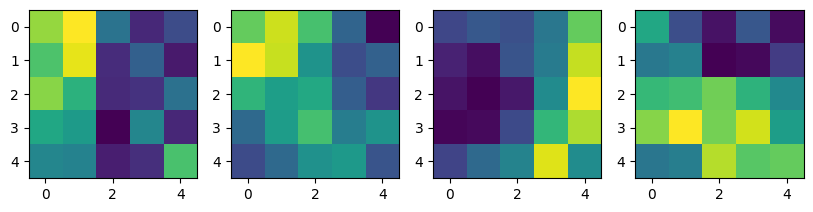
第一个卷积层后的特征图:
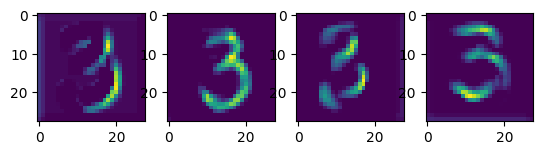
第二个卷积层后的特征图: