ADB-Index Structure
Index Structure
Hash
Static Hash Schemes
Linear Probe Hashing
Redundant Keys:
将 key 和 value 合并在一起作为 key,避免key重复
Sperate Linked List:
一个 key 指向一个 value list
删除:
- 墓碑标记
- 重新整理
Robin Hood Hashing
- 每个 value 记录偏移了多少格。当插入某个元素遇到冲突时,挤占偏移少的 value 格子
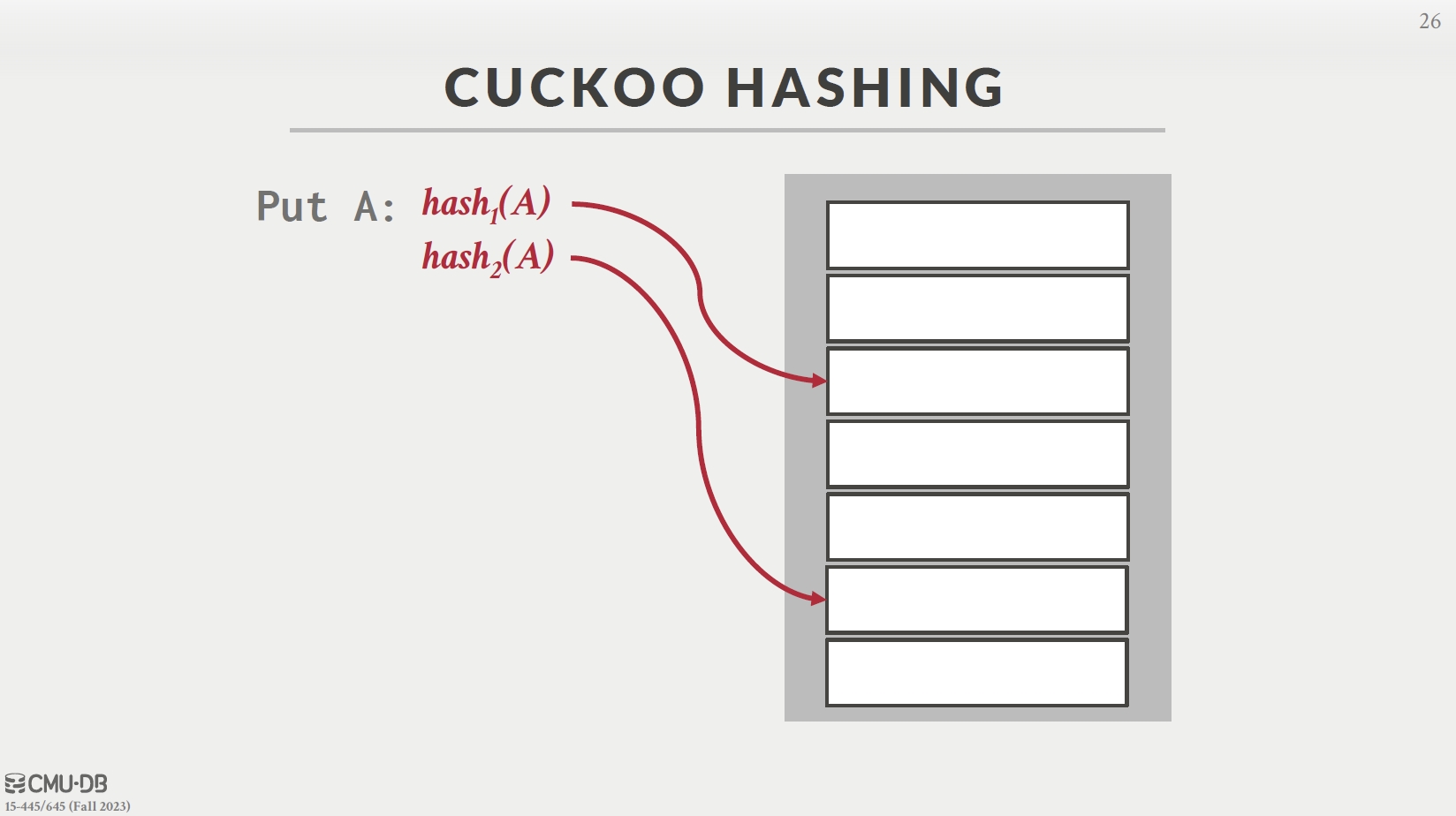
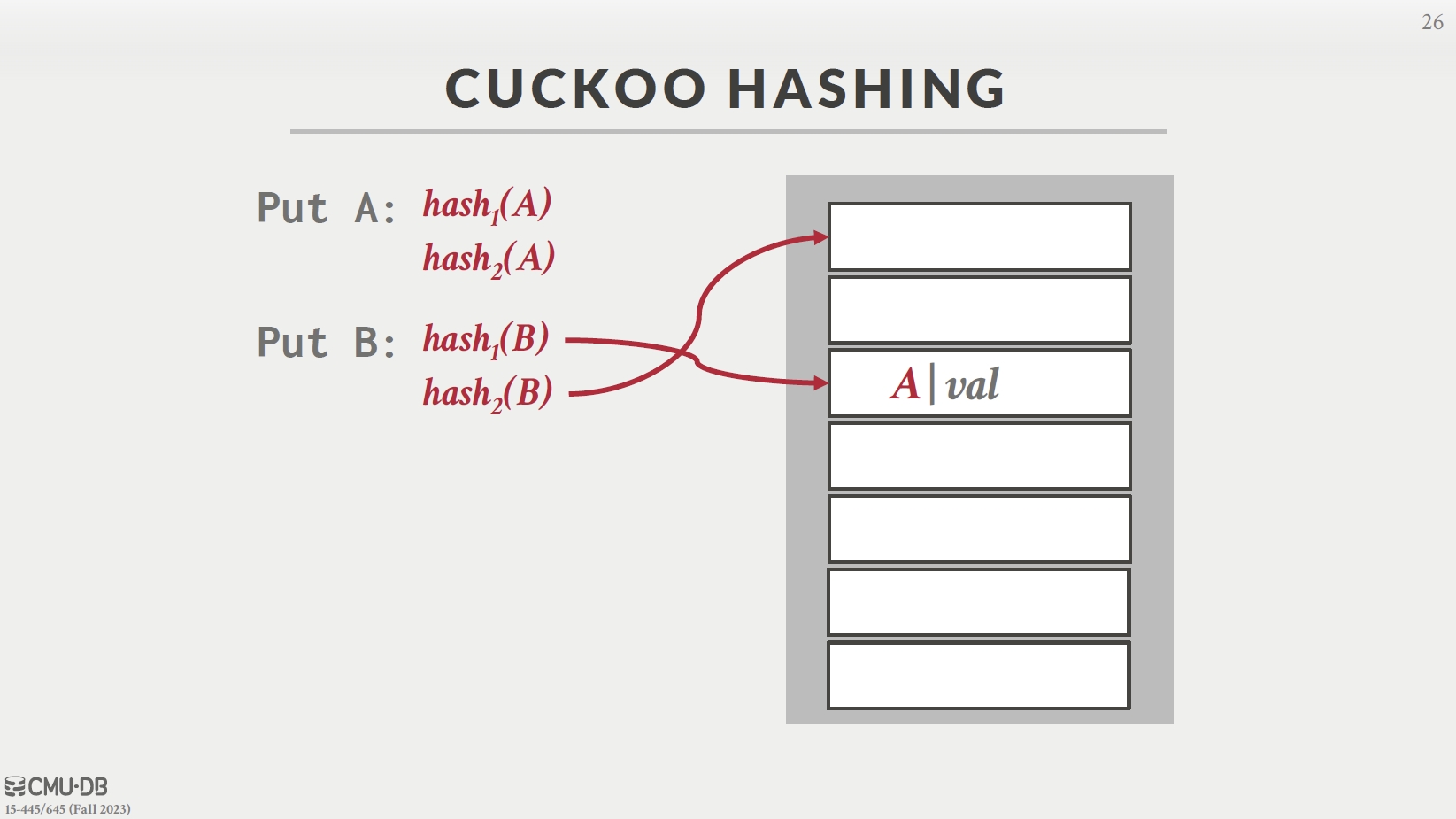
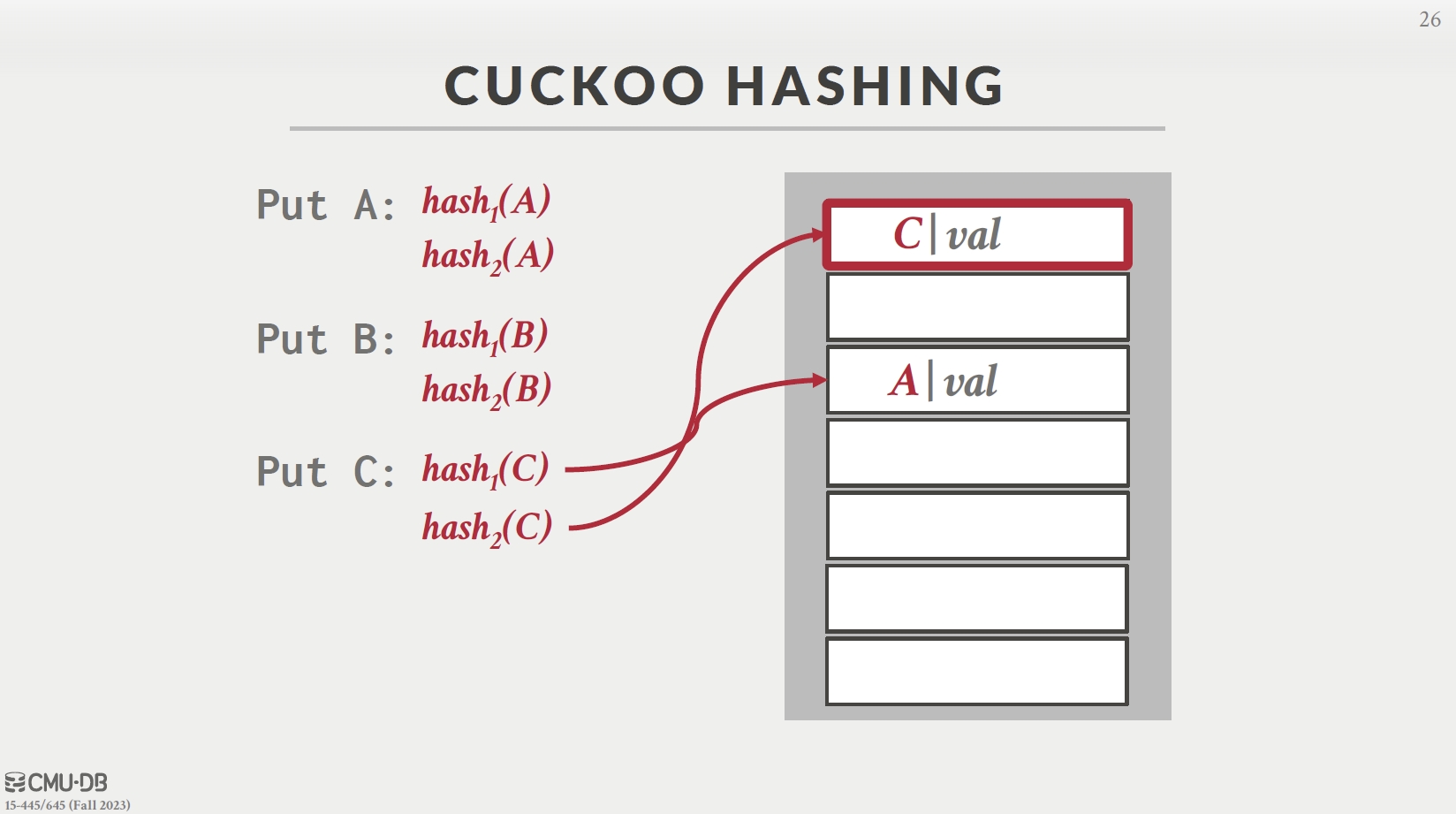
Cuckoo Hashing
- 两个哈希表 1、2,A 进 1,B 和 A 在 1 冲突, B 进 2
- C 和 A、B 都冲突,C 挤占 B,B 挤占 A,A 进 2(两个表哈希函数不同)
 |
 |
|---|---|
 |
 |
Dynamic Hash Tables
Chained Hashing
- 拉链法
- Java HashMap: 拉链法 + 红黑树 + 扩容哈希
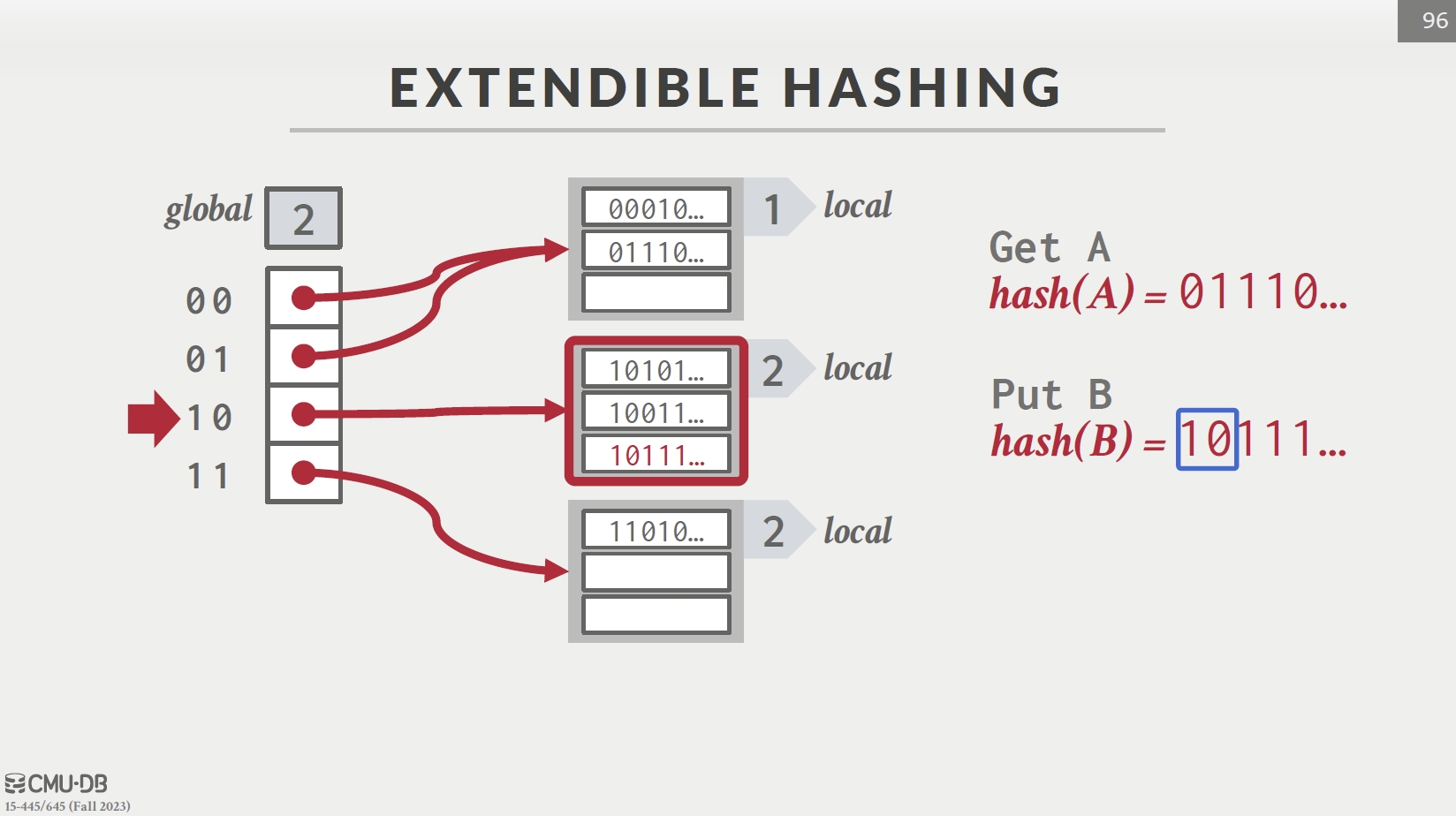
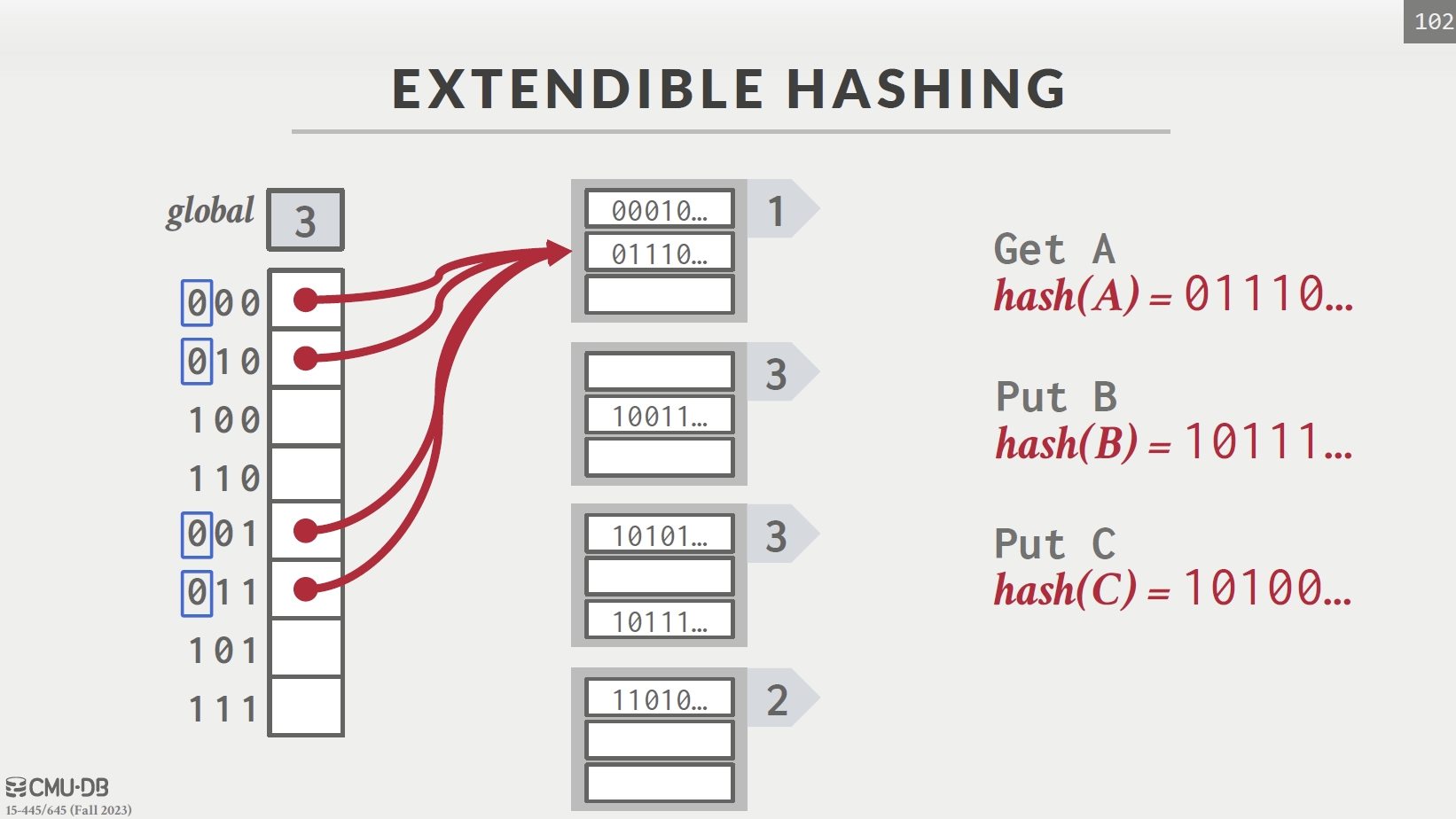
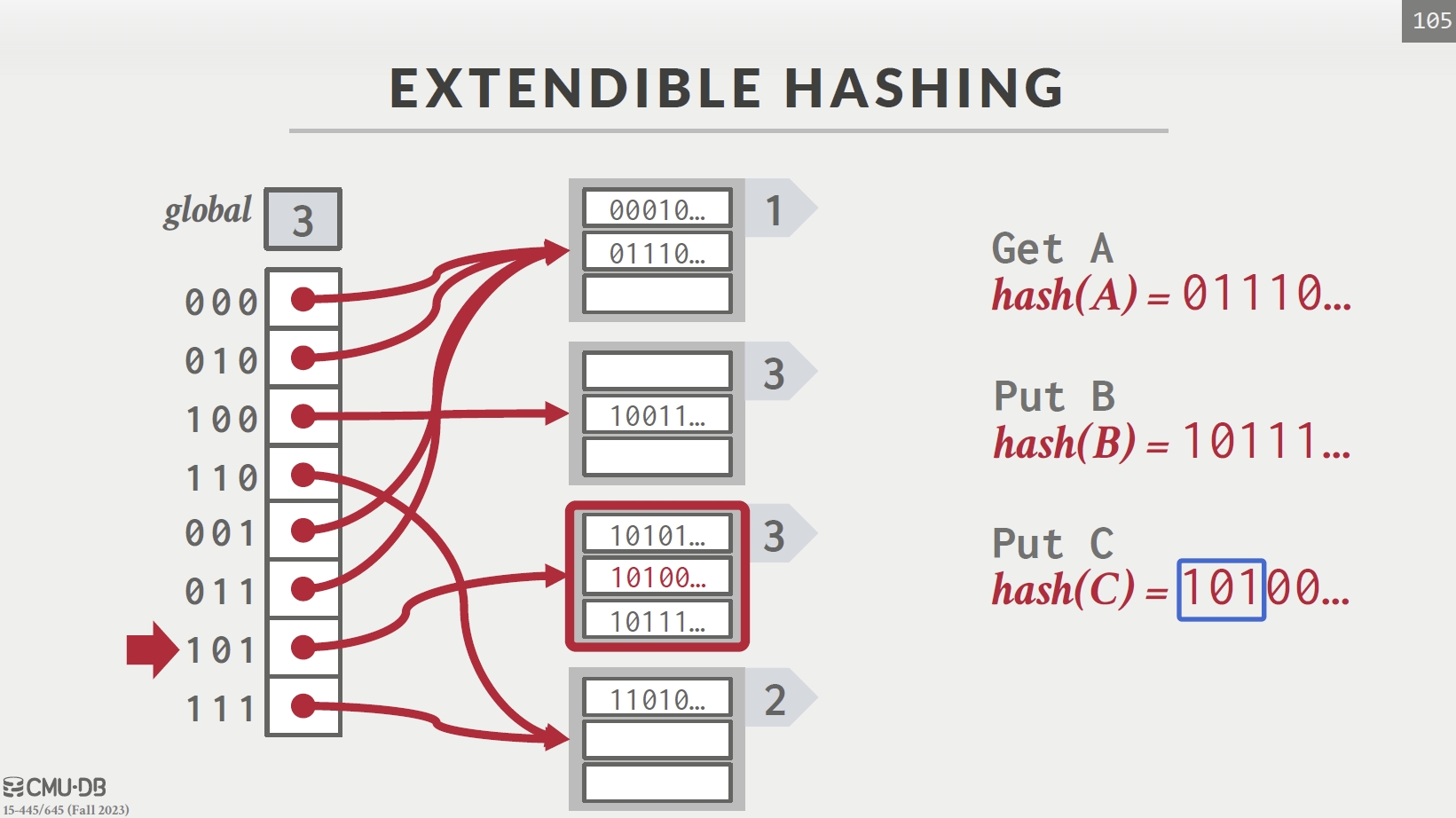
Extendible Hashing
- 散列函数 h(k) 是一个 b 位二进制序列,前 i 位表示桶的数目
- 从i=1开始分配桶数量(2个),若桶数量不够时,则会增加 i 并重新分配桶内元素
 |
 |
 |
|---|
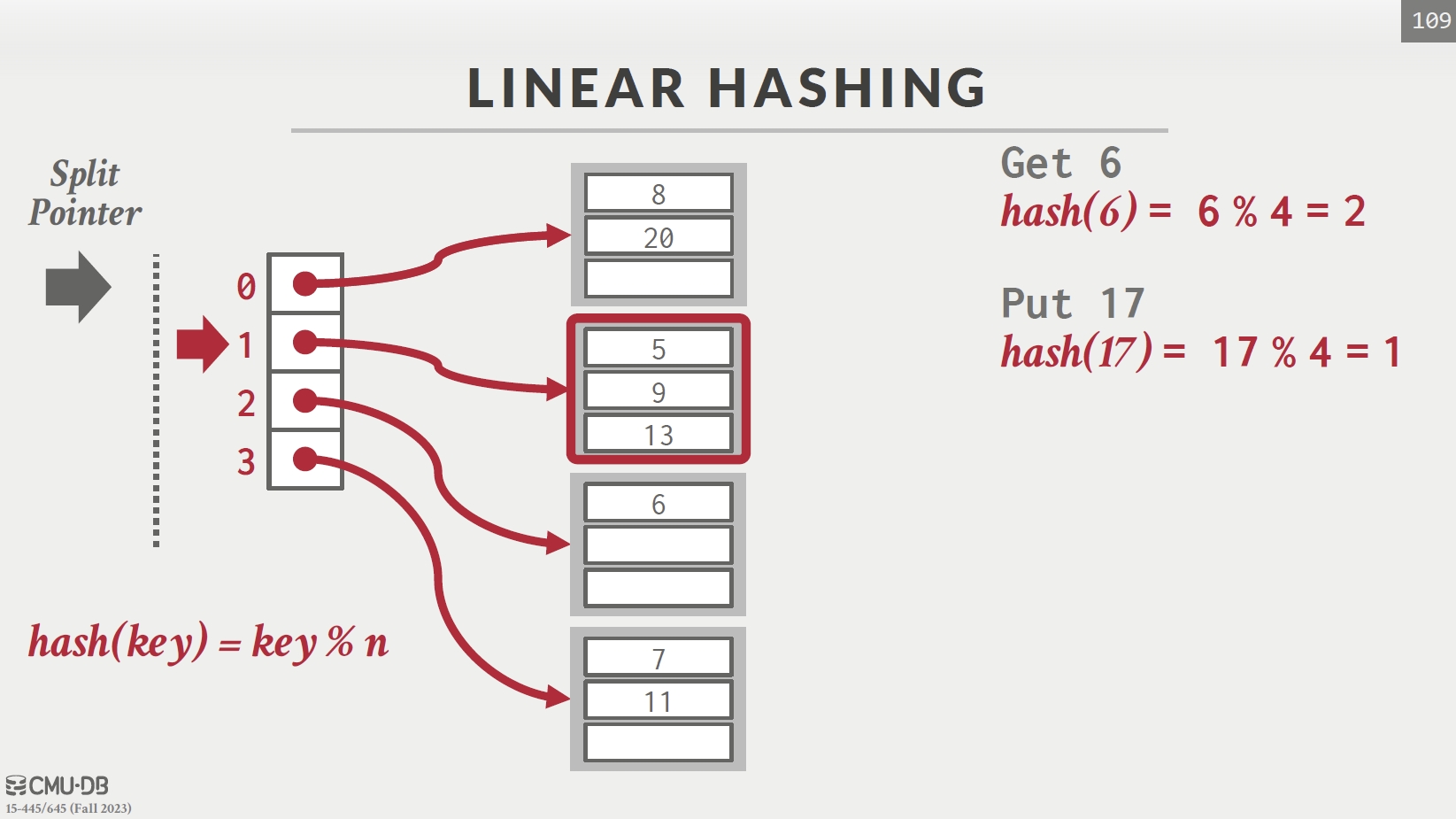
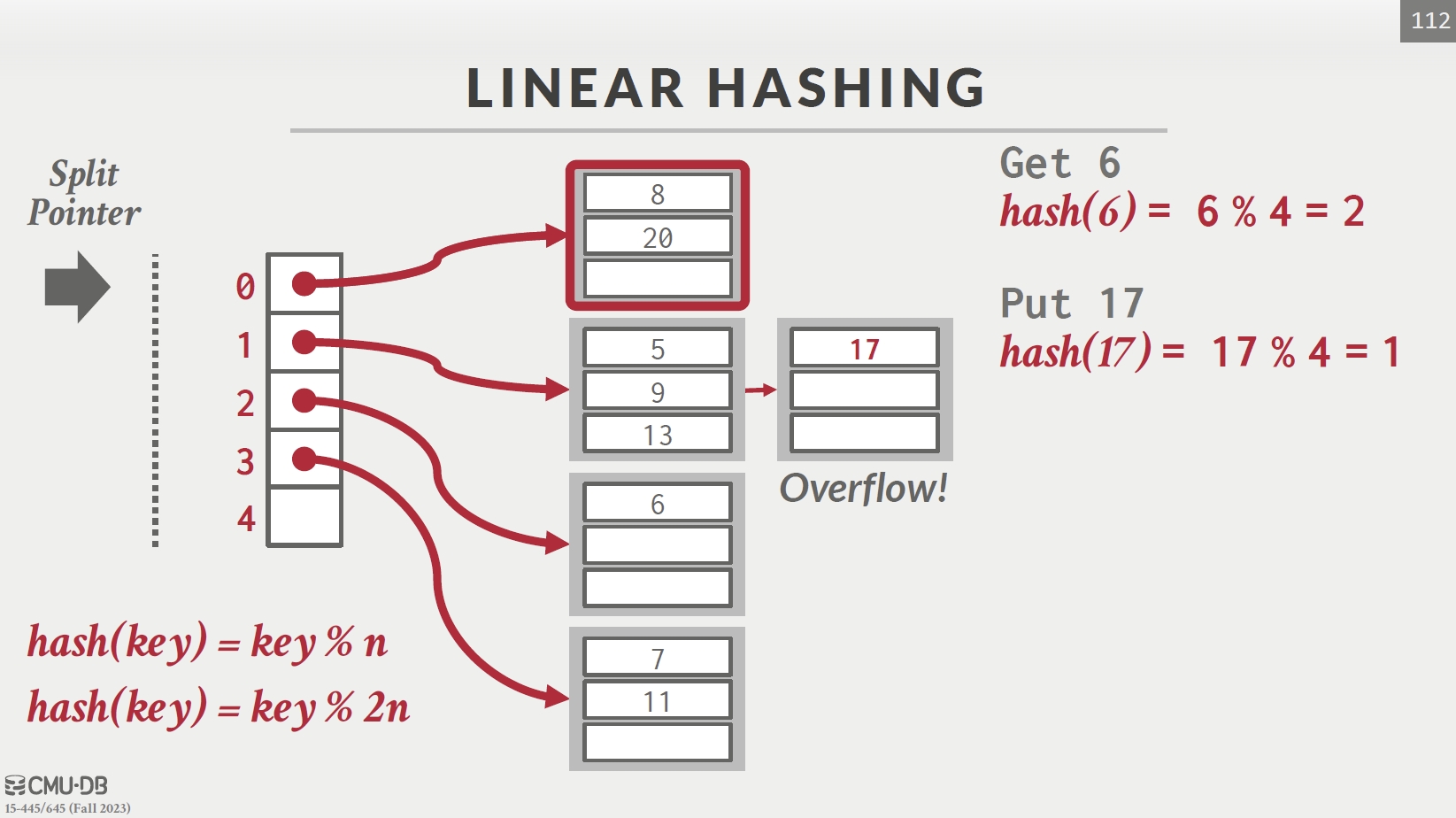
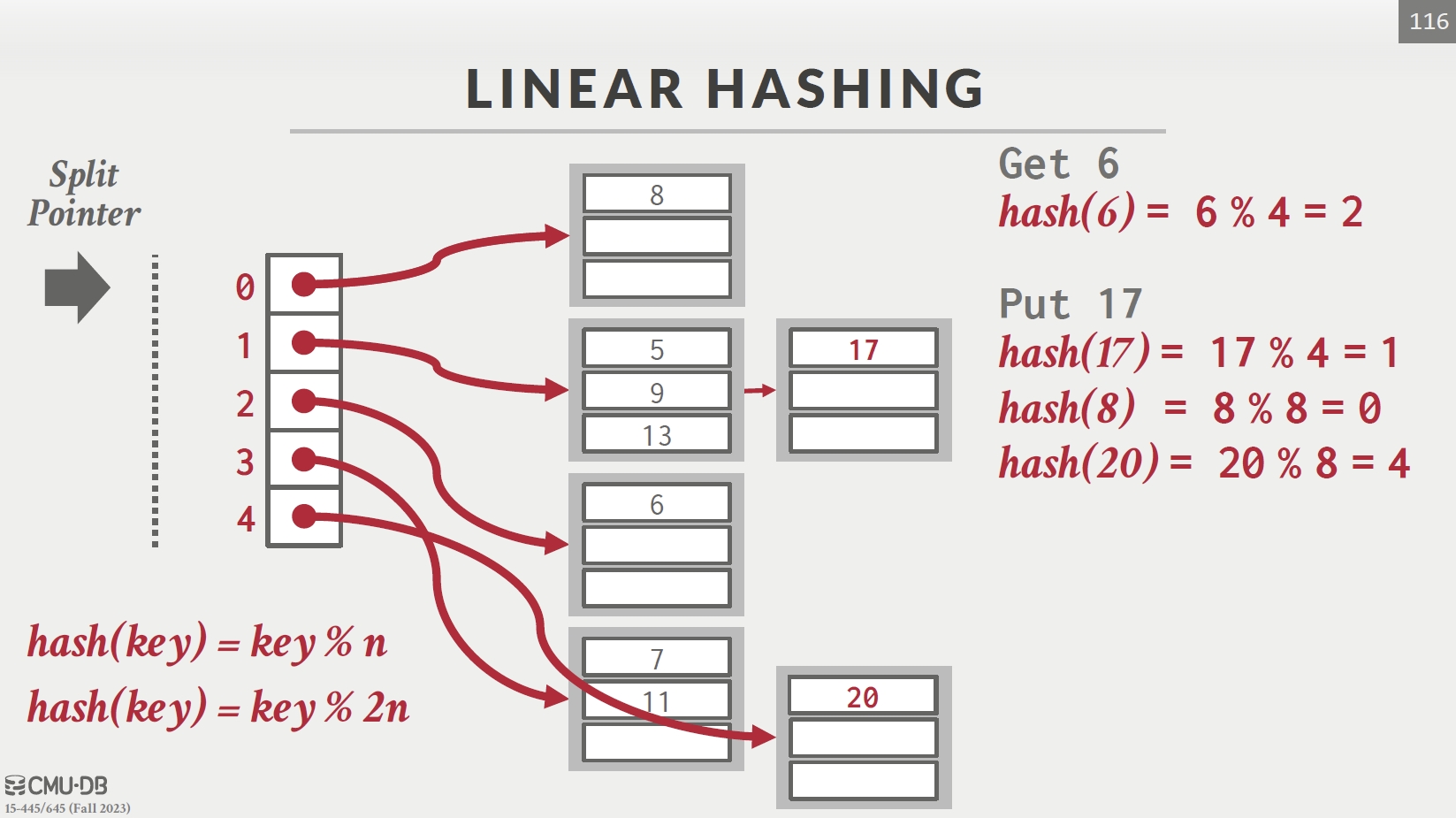
Linear Hashing
| Pointer 指向 0 | 发生冲突,添加溢出表 |
|---|---|
 |
 |
| Pointer 指向的格子分家 | Pointer 下移 |
 |
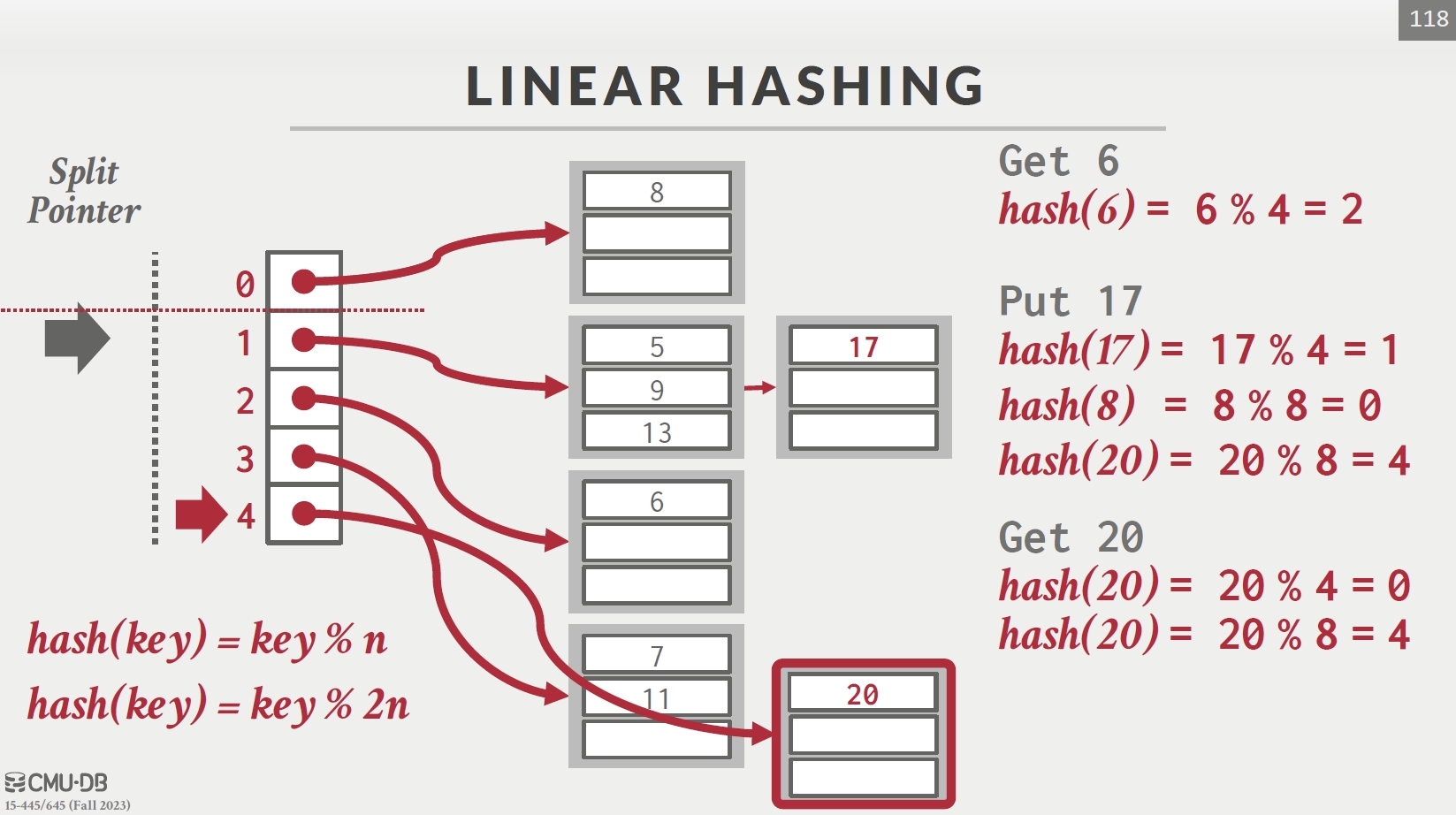 |
对所有 key 先按 hash1 寻找,若在 Pointer 上方则改用 hash2 寻找,若在下方则不变。
每次发生冲突,指针下移一格。一趟分家完重回最开始位置。
B+Tree
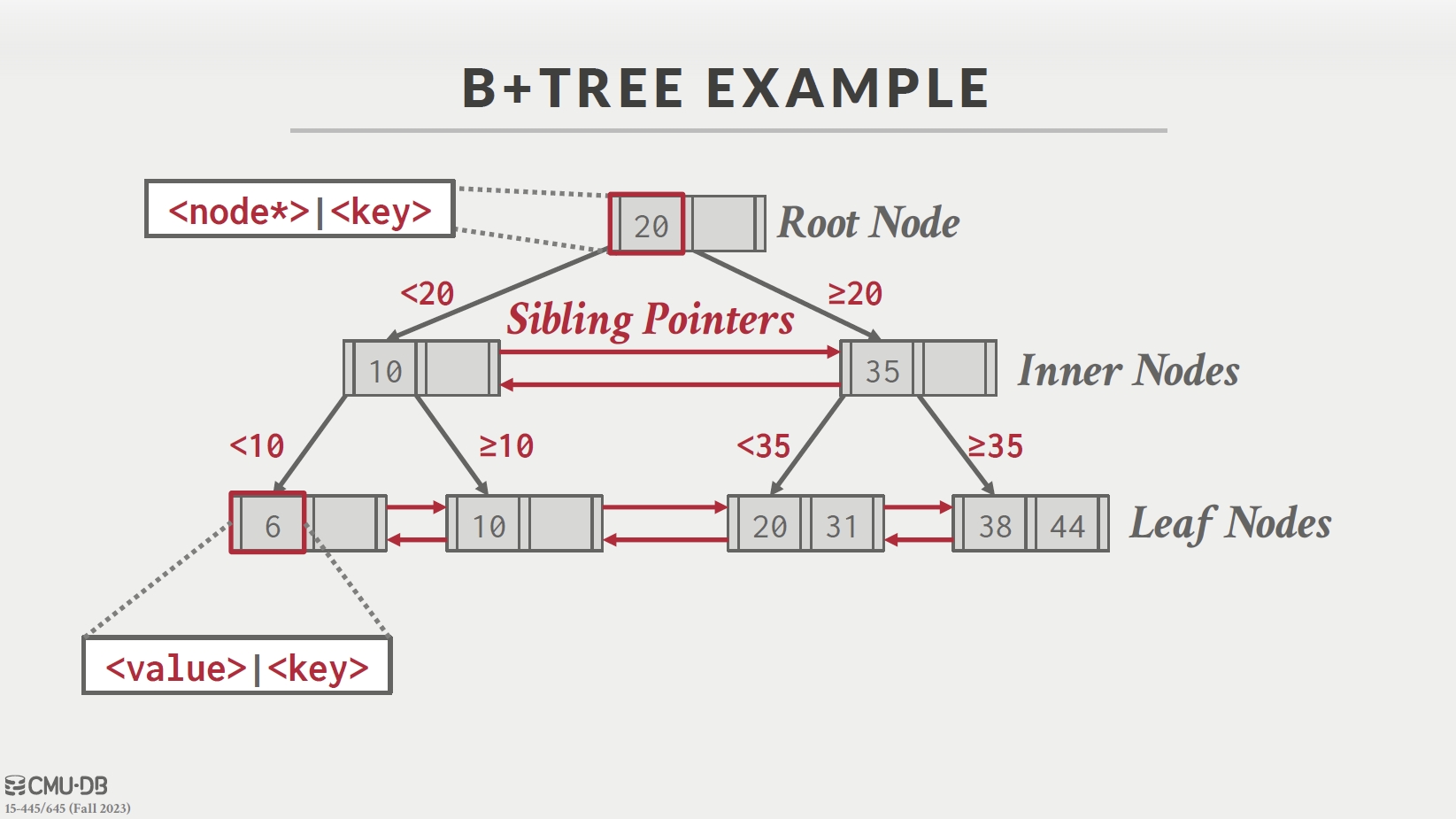
Node
key/value pairs
Leaf Node:
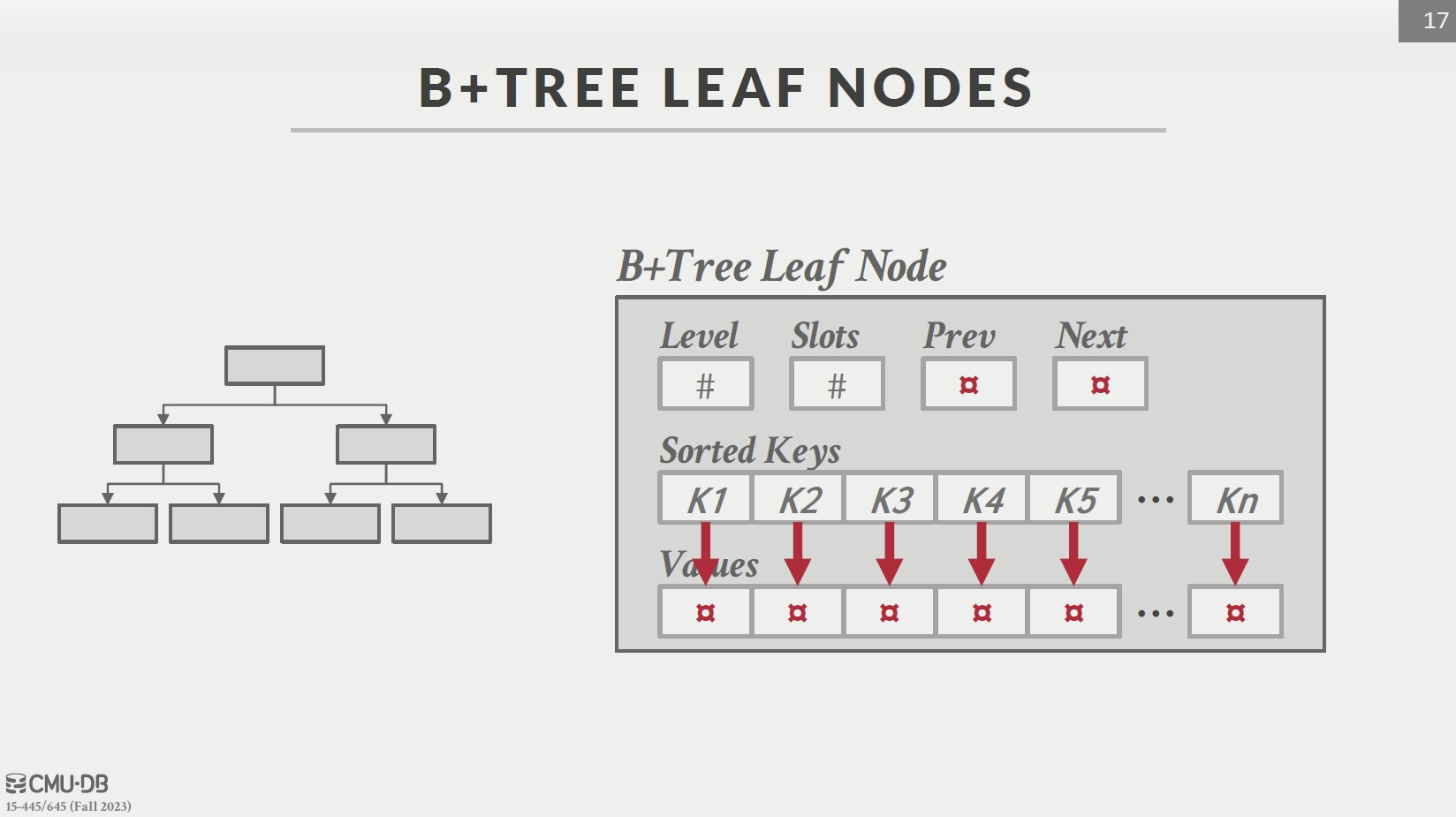
Leaf Node Values:
- Record IDs
- Tuple Data
B+Tree 只在叶子节点存取 values。内部节点只负责搜索。
Duplicate Keys
- 与RecordID组合形成新键
- 溢出叶子节点
Clustered Indexes
表格根据主键按序存储。
Variable Length Keys
- 存储索引值的指针
- 填充 key 达到最大长度
Intra Node Search
Linear
Binary
Interpolation:根据已知键值估算
Optimizations
- 前缀压缩
- 将新加的值构建 B+Tree,再 Merge 到主 B+Tree 中
- 有重复 key 的情况下,只存一个 key,对应多个 value
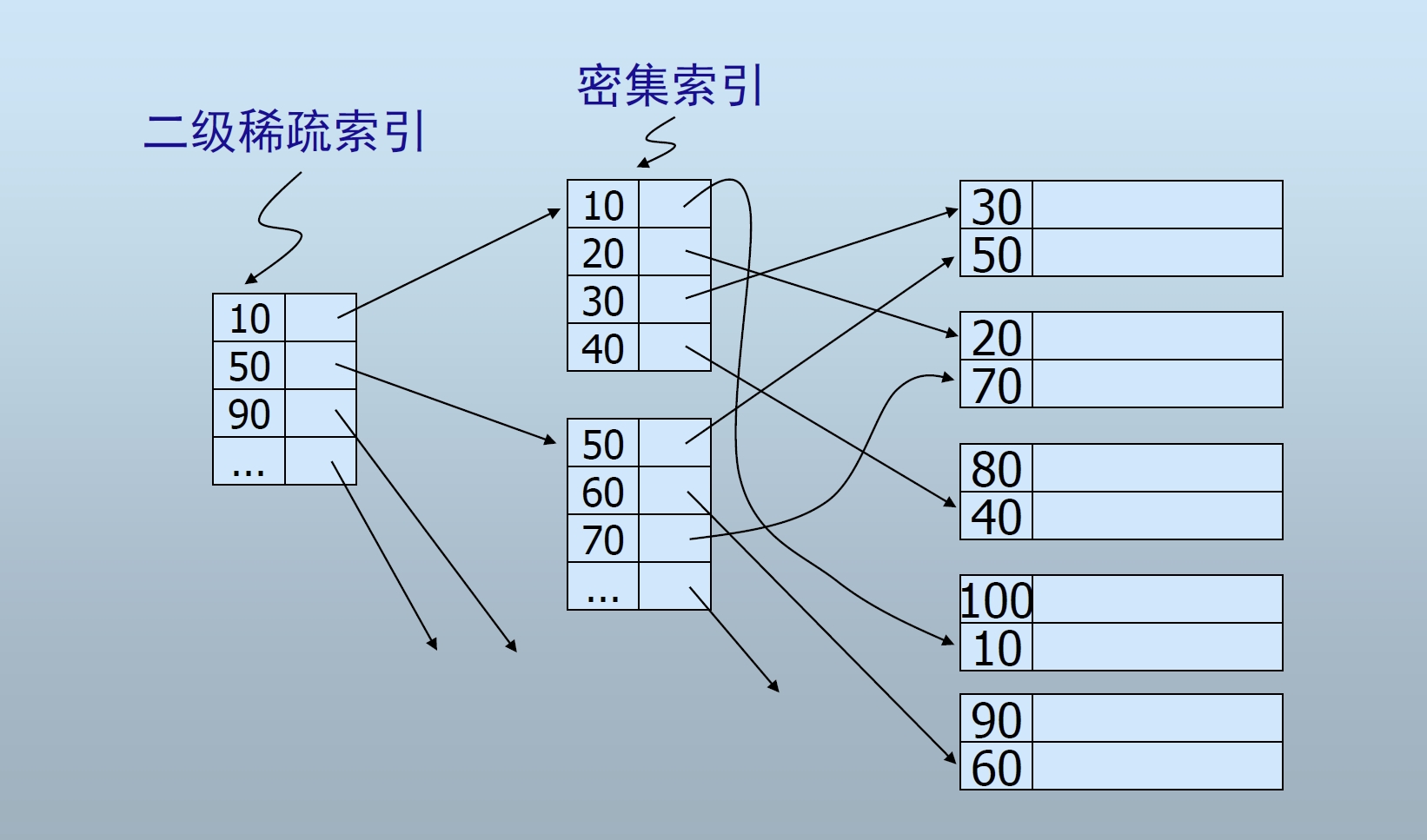
Sequential File Index
Dense Index:密集索引
Sparse Index:稀疏索引
Multi-Level Index:多级索引
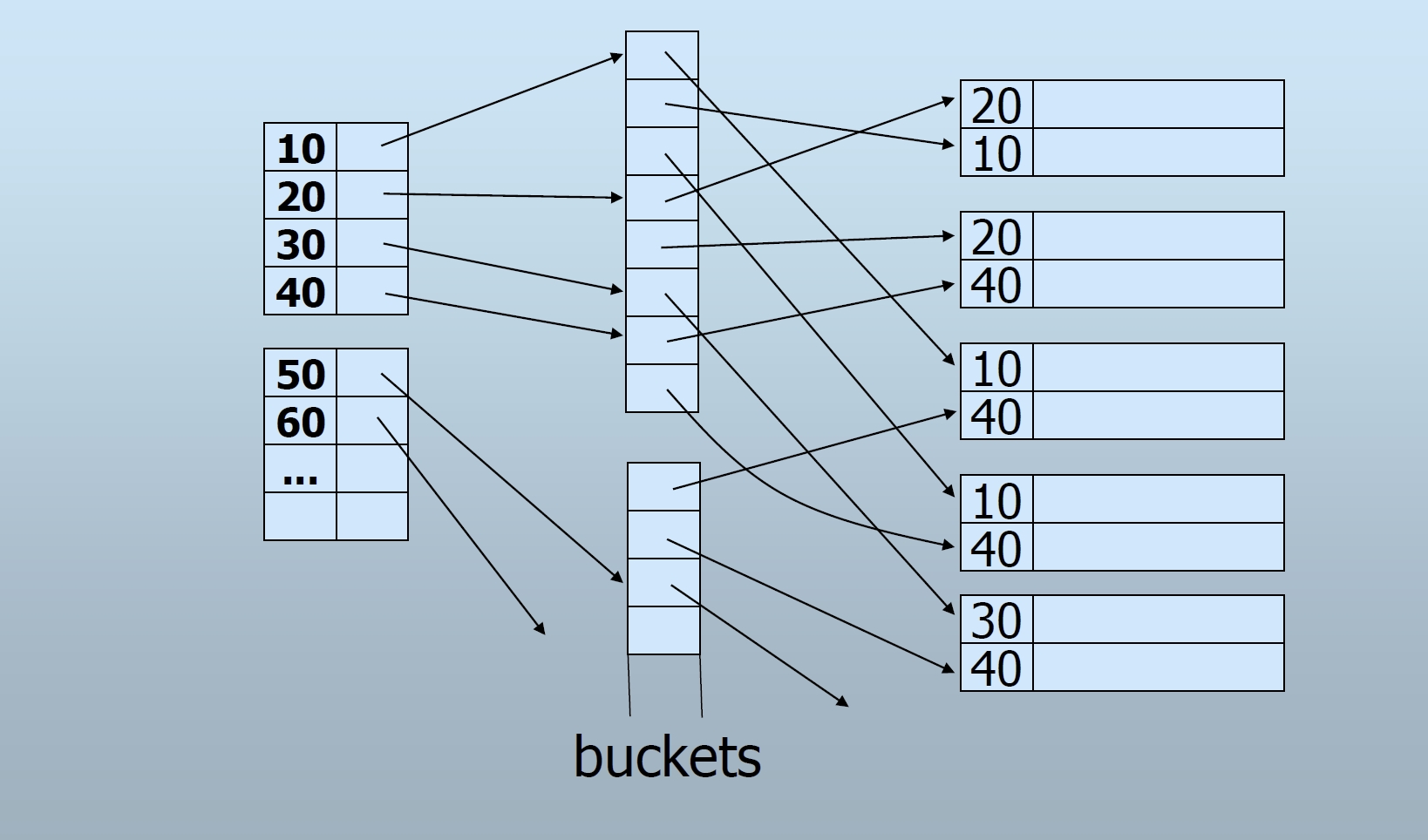
Secondary Index
数据文件不需要按查找键有序排列
辅助索引只能是密集索引
重复键值:间接桶
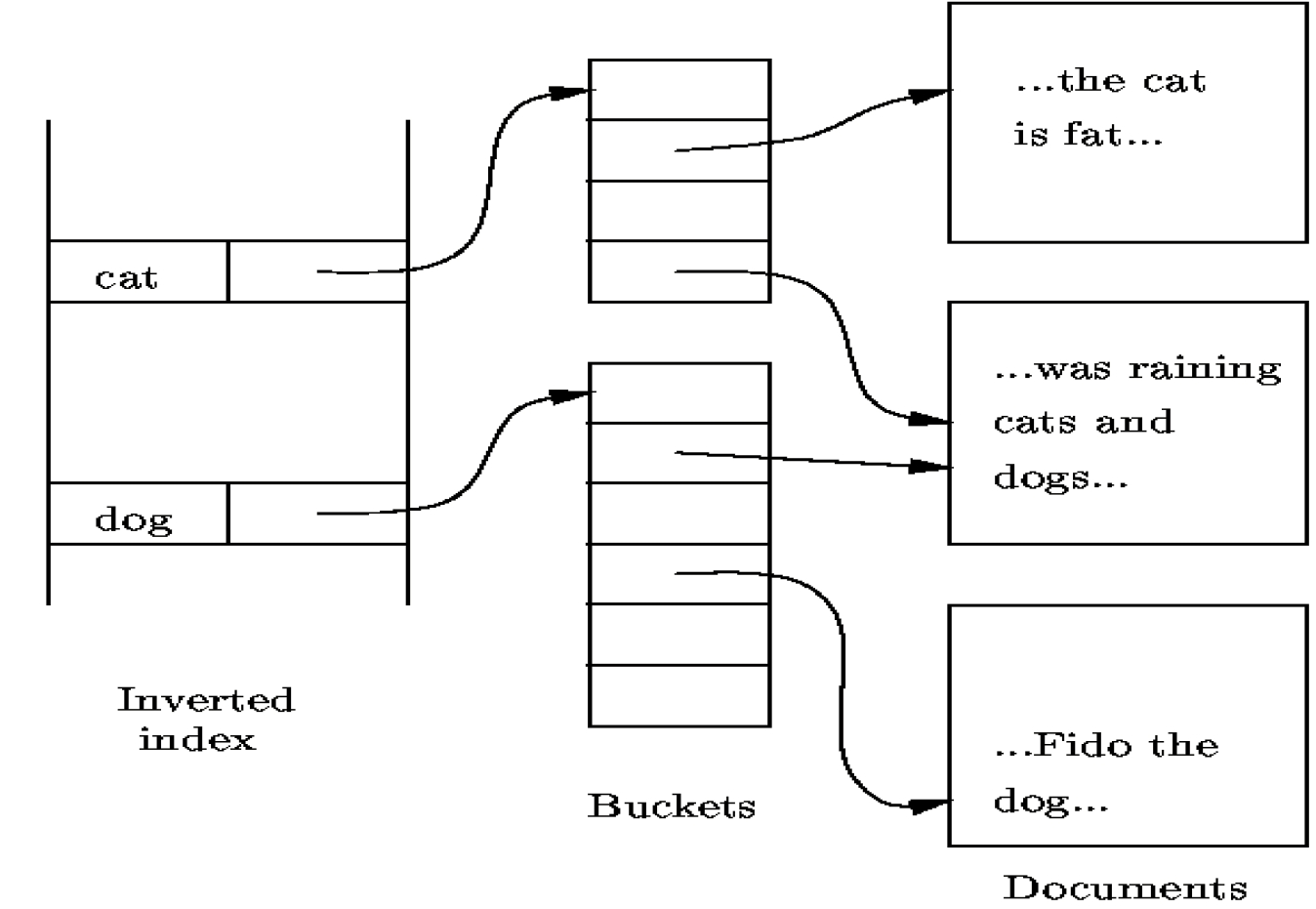
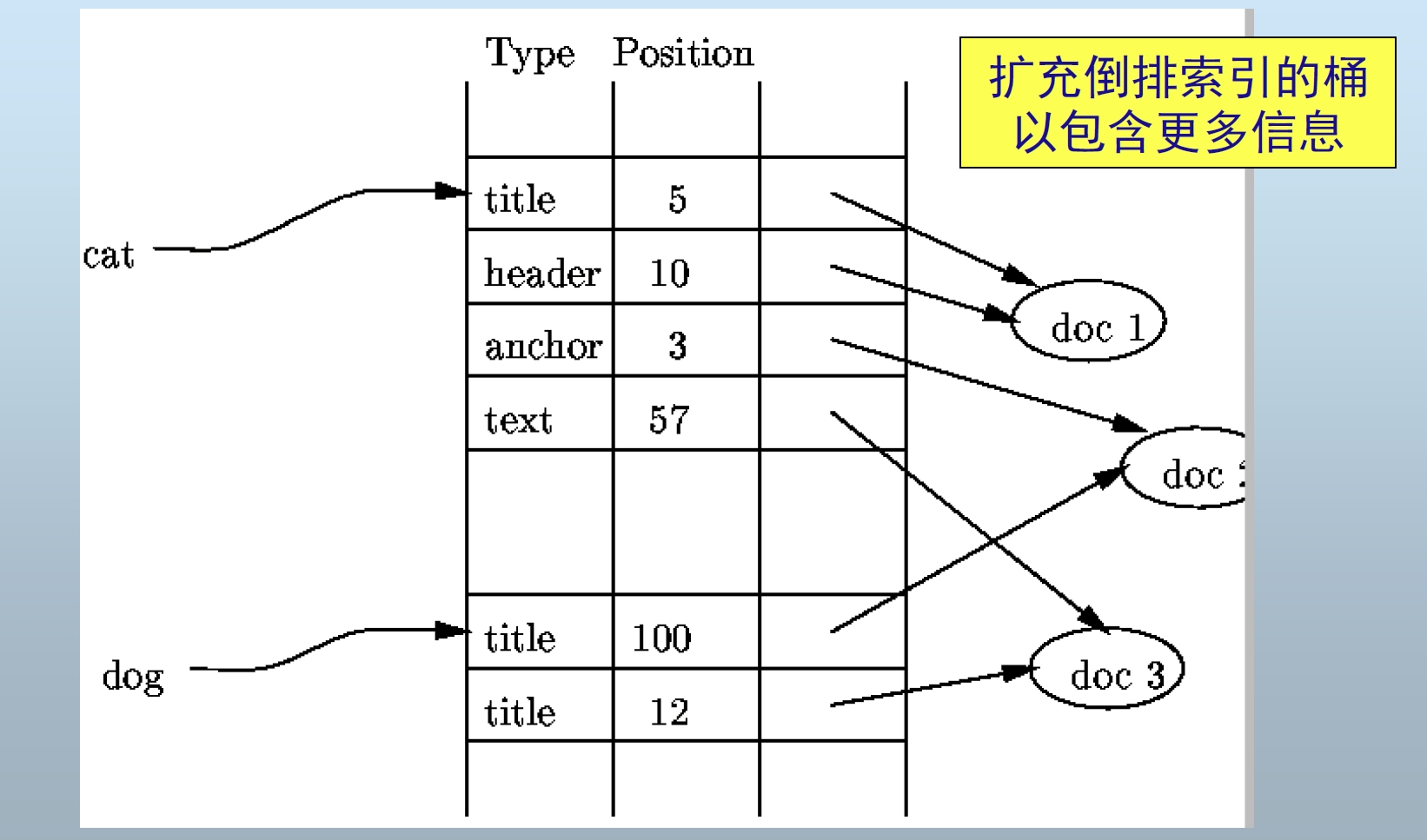
Inverted Index
- 应用于文档检索,与辅助索引思想类似
- 思想:为每个检索词建立间接桶,桶的指针指向检索词所出现的文档