DL-共享单车预测
共享单车预测
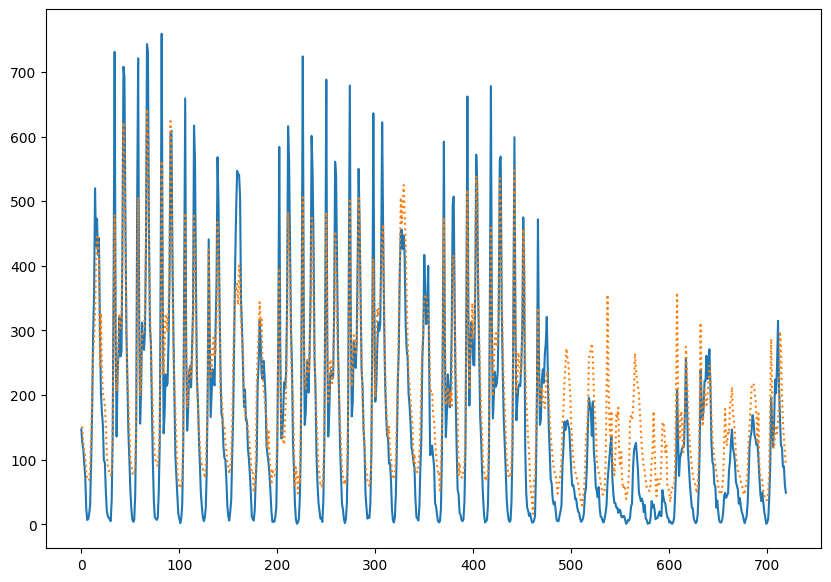
通过历史数据预测某一地区接下来一段时间内的共享单车的数量。首先对数据进行预处理,然后在训练集上训练,并在测试集上验证模型。设计神经网络数据进行拟合,利用训练后的模型对数据拟合并进行预测, 记录误差,并绘制出拟合效果。
导包
1 | import torch |
文件形式:
离散数据处理
通过 pd.get_dummies 函数,对指定的几个列进行了独热编码。独热编码是一种将分类变量转换为二进制向量的方法,以便更好地在机器学习模型中使用。循环中的每个列都进行了独热编码,并将结果与原始数据框进行连接(pd.concat)。
1 | data = pd.read_csv('bikes.csv') |
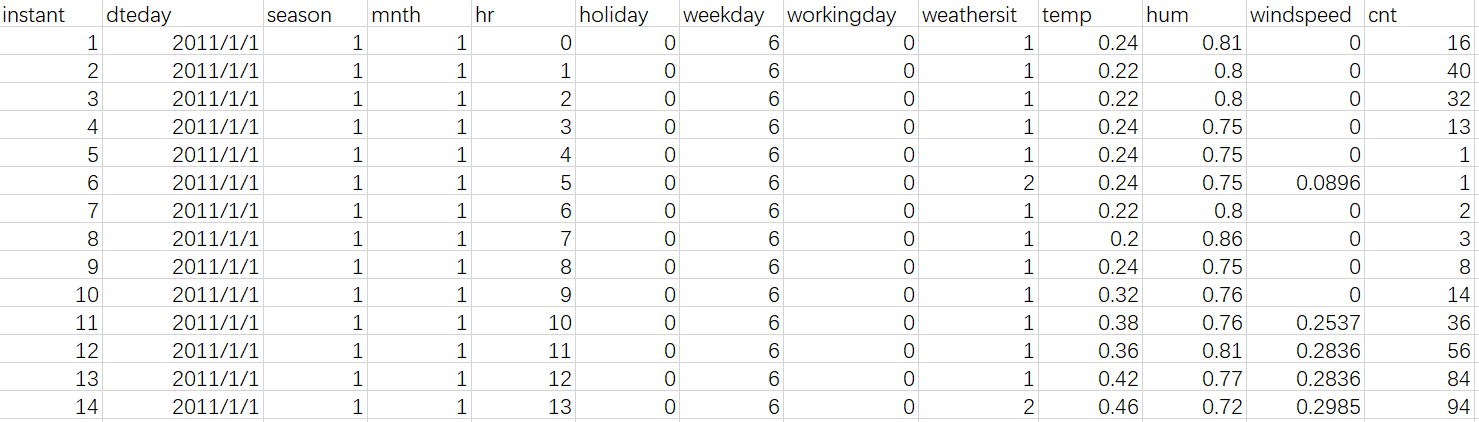
离散数据处理后的 data:
holiday temp hum windspeed cnt season_1 season_2 season_3 \
0 0 0.24 0.81 0.0 16 True False False
1 0 0.22 0.80 0.0 40 True False False
2 0 0.22 0.80 0.0 32 True False False
3 0 0.24 0.75 0.0 13 True False False
4 0 0.24 0.75 0.0 1 True False False
season_4 weathersit_1 ... hr_21 hr_22 hr_23 weekday_0 weekday_1 \
0 False True ... False False False False False
1 False True ... False False False False False
2 False True ... False False False False False
3 False True ... False False False False False
4 False True ... False False False False False
weekday_2 weekday_3 weekday_4 weekday_5 weekday_6
0 False False False False True
1 False False False False True
2 False False False False True
3 False False False False True
4 False False False False True
[5 rows x 56 columns]
连续数据标准化处理
标准化:
- 对于每个列,使用循环进行以下操作:
mean, std = data[i].mean(), data[i].std()计算当前列的均值(mean)和标准差(std)。data[i] = (data[i] - mean) / std对当前列进行标准化处理,即将每个元素减去均值并除以标准差。通过标准化,将每个特征的值调整为均值为0,标准差为1的分布,从而使得它们的数值范围相对一致。有助于训练某些机器学习模型。
1 | col_titles = ['cnt', 'temp', 'hum', 'windspeed'] |
连续数据处理后:
cnt temp hum windspeed
0 -0.956312 -1.334609 0.947345 -1.553844
1 -0.823998 -1.438475 0.895513 -1.553844
2 -0.868103 -1.438475 0.895513 -1.553844
3 -0.972851 -1.334609 0.636351 -1.553844
4 -1.039008 -1.334609 0.636351 -1.553844
... ... ... ... ...
17374 -0.388467 -1.230743 -0.141133 -0.211685
17375 -0.553859 -1.230743 -0.141133 -0.211685
17376 -0.548346 -1.230743 -0.141133 -0.211685
17377 -0.708224 -1.230743 -0.348463 -0.456086
17378 -0.774381 -1.230743 0.118028 -0.456086
[17379 rows x 4 columns]
数据集处理
按11:1划分
1 | test_data = data[-30*24:] |
搭建神经网络
1 | input_size = X.shape[1] |
训练
batch:小批量梯度下降
1 | losses = [] |
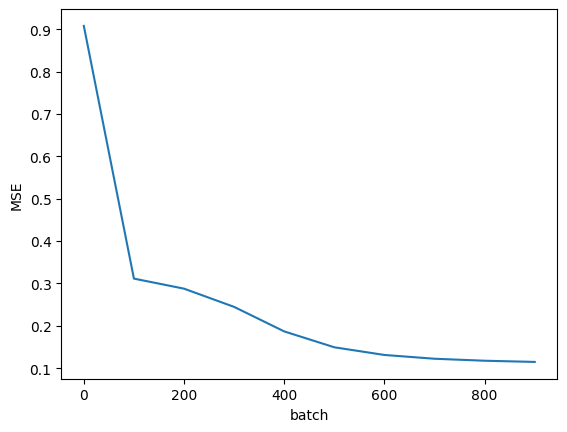
训练时损失:
0 0.9076614
100 0.3113705
200 0.28764674
300 0.24460928
400 0.18675153
500 0.14928792
600 0.13117069
700 0.12224861
800 0.117569864
900 0.114756
测试
Y = Y.values.reshape([len(Y), 1]):Y.values将 pandas 数据框中的目标变量Y转换为 NumPy 数组。reshape([len(Y), 1])将目标变量Y从一维数组调整为二维数组,其中列数为 1。这是因为 PyTorch 中的目标变量通常被期望是一个二维张量,其中每行代表一个样本,每列代表一个目标值。这有助于与模型的输出格式匹配。
X = torch.FloatTensor(X.values):X.values将 pandas 数据框中的特征变量X转换为 NumPy 数组。torch.FloatTensor()将 NumPy 数组转换为 PyTorch 的浮点张量。神经网络的输入通常需要是浮点数类型,因此这一步确保了输入数据的类型正确。
1 | X = test_data.drop(['cnt'], axis=1) |
预测对比: