聚类与分类 通过 sklearn 库提供的聚类算法生成 K 类数据,以这些数据作为数据集训练神经网络,利用 softmax 层和交叉熵损失函数对数据进行分类。聚类参数要求 k>3,数据样本不少于 1000,对聚类后的数据按 9:1 的原则划分训练集和测试集,利用在训练集上训练得到的模型对测试集上的数据进行验证。
导包 1 2 3 4 5 6 7 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import Dataset, DataLoader, TensorDatasetfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt
生成数据
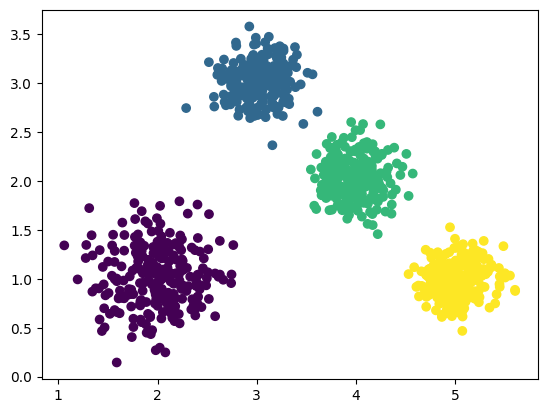
data 为样本特征,**target ** 为样本簇类别make_blobs: 共 1000 个样本,每个样本 2 个特征,共 3 个簇,簇中心在 [2,1],[3,3],[4,2],[5,1], 簇方差分别为 [0.3,0.2,0.2,0.2] plt.scatter: 将数据集的散点图可视化,c=target 代表不同簇不同颜色,data[:, 0] 为特征 1 ,表示 x 轴, data[:, 1] 为特征 2 ,表示 y 轴
1 2 3 4 data, target = make_blobs(n_samples=500 , n_features=2 , centers=[[2 ,1 ],[3 ,3 ],[4 ,2 ],[5 ,1 ]], cluster_std=[0.3 , 0.2 , 0.2 , 0.2 ], random_state=8 ) plt.scatter(data[:,0 ], data[:,1 ], c=target, marker='o' ) plt.show()
数据准备
数据类型转换 :
data = torch.from_numpy(data) 将 NumPy 数组 data 转换为 PyTorch 张量。这是因为 PyTorch 中的神经网络模型和训练过程一般使用张量作为输入和输出。data = data.type(torch.FloatTensor) 将数据类型转换为 torch.FloatTensor。这一步是为了确保数据在 PyTorch 中是浮点数类型。
标签类型转换 :
target = torch.from_numpy(target) 类似地将 NumPy 数组 target 转换为 PyTorch 张量。target = target.type(torch.LongTensor) 将标签的数据类型转换为 torch.LongTensor。在分类问题中,标签通常是整数,因此需要使用长整型。
构建 TensorDataset 对象 :
train_dataset = TensorDataset(train_x, train_y) 创建一个 PyTorch 的 TensorDataset 对象,将训练集的特征 train_x 和标签 train_y 组合在一起。
构建 DataLoader 对象 :
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True) 创建一个训练集的 DataLoader,用于以小批量的方式遍历训练集。batch_size 参数指定了每个小批量的样本数,shuffle=True 表示每个周期都打乱数据顺序,增加训练的随机性。
1 2 3 4 5 6 7 8 9 10 11 12 13 data = torch.from_numpy(data) data = data.type (torch.FloatTensor) target = torch.from_numpy(target) target = target.type (torch.LongTensor) train_x = data[:900 ] train_y = target[:900 ] test_x = data[900 :1000 ] test_y = target[900 :1000 ] train_dataset = TensorDataset(train_x, train_y) test_dataset = TensorDataset(test_x, test_y) train_loader = DataLoader(dataset=train_dataset, batch_size=32 , shuffle=True ) test_loader = DataLoader(dataset=test_dataset, batch_size=16 , shuffle=True )
构建神经网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Model (nn.Module): def __init__ (self ): super ().__init__() self.hidden1 = nn.Linear(2 , 5 ) self.out = nn.Linear(5 , 4 ) def forward (self, x ): x = self.hidden1(x) x = F.relu(x) x = self.out(x) return x net = Model() loss_fn = nn.CrossEntropyLoss() opt = torch.optim.SGD(net.parameters(), lr=0.01 )
训练 1 2 3 4 5 6 7 8 9 10 11 12 for epoch in range (1000 ): for i, data in enumerate (train_loader): x, y = data pred = net(x) loss = loss_fn(pred, y) opt.zero_grad() loss.backward() opt.step() if epoch % 100 == 0 : print (loss)
训练期间损失输出: tensor(1.3498, grad_fn=<NllLossBackward0>)
tensor(0.3730, grad_fn=<NllLossBackward0>)
tensor(0.0557, grad_fn=<NllLossBackward0>)
tensor(0.0430, grad_fn=<NllLossBackward0>)
tensor(0.0495, grad_fn=<NllLossBackward0>)
tensor(0.0122, grad_fn=<NllLossBackward0>)
tensor(0.0161, grad_fn=<NllLossBackward0>)
tensor(0.0510, grad_fn=<NllLossBackward0>)
tensor(0.0151, grad_fn=<NllLossBackward0>)
tensor(0.0887, grad_fn=<NllLossBackward0>)
预测 batch = 16 为一组
torch.max: 每个样本输出成概率分布,沿着 1 维度搜索最大值以确定类别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def rightness (_pred, _y ): _pred = torch.max (_pred.data, 1 )[1 ] _rights = _pred.eq(_y.data.view_as(_pred)).sum () return _rights, len (_y) rights = 0 length = 0 for i, data in enumerate (test_loader): x, y = data pred = net(x) rights = rights+rightness(pred, y)[0 ] length = length+rightness(pred, y)[1 ] print (y) print (torch.max (pred.data, 1 )[1 ], '\n' ) print (rights, length, rights/length)
预测正确率: tensor([0, 2, 1, 0, 1, 2, 0, 2, 0, 3, 0, 1, 1, 1, 2, 2])
tensor([0, 2, 1, 0, 1, 2, 0, 2, 0, 3, 0, 1, 1, 1, 2, 2])
tensor([1, 1, 1, 1, 3, 2, 1, 0, 1, 2, 0, 3, 3, 0, 3, 1])
tensor([1, 1, 1, 1, 3, 2, 1, 0, 1, 2, 0, 3, 3, 0, 3, 1])
tensor([1, 2, 1, 0, 0, 1, 3, 3, 1, 0, 2, 0, 2, 3, 2, 0])
tensor([1, 2, 1, 0, 0, 1, 3, 3, 1, 0, 2, 0, 2, 3, 2, 0])
tensor([1, 3, 3, 0, 0, 2, 2, 2, 0, 0, 0, 2, 1, 2, 1, 3])
tensor([1, 3, 3, 0, 0, 2, 2, 2, 0, 0, 0, 2, 1, 2, 1, 3])
tensor([3, 2, 3, 2, 0, 0, 3, 2, 3, 3, 2, 0, 2, 3, 1, 0])
tensor([3, 2, 3, 2, 0, 0, 3, 2, 3, 3, 2, 0, 2, 3, 1, 0])
tensor([3, 3, 2, 3, 3, 3, 0, 3, 2, 1, 0, 0, 2, 0, 0, 1])
tensor([3, 3, 2, 3, 3, 3, 0, 3, 2, 1, 0, 0, 2, 0, 0, 1])
tensor([1, 1, 0, 3])
tensor([1, 1, 0, 3])
tensor(100) 100 tensor(1.)