正弦函数预测 通过已知的样本数据对正弦函数进行预测,并绘制出图形。分别设计 LSTM GRU和 RNN网络进行预测。
导包 1 2 3 4 5 6 import numpy as npimport torchfrom torch.utils.data import TensorDatasetfrom torch.utils.data import DataLoaderimport torch.nn as nnimport matplotlib.pyplot as plt
数据集生成与划分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 data = [] start = 0 for i in range (200 ): x = [np.sin(x/10 ) for x in range (start, start+11 )] data.append(x) start = start + 1 data = np.array(data) data = torch.from_numpy(data) target = data[:, -1 :].type (torch.FloatTensor) data = data[:, :-1 ].type (torch.FloatTensor) train_x = data[:150 ] train_y = target[:150 ] test_x = data[150 :] test_y = target[150 :] train_dataset = TensorDataset(train_x, train_y) test_dataset = TensorDataset(test_x, test_y) train_loader = DataLoader(dataset=train_dataset, batch_size=5 , shuffle=True ) test_loader = DataLoader(dataset=test_dataset, batch_size=5 , shuffle=False )
网络构建
nn.RNN(1, 10, batch_first=True): RNN是最基本的循环神经网络结构。它的每个时间步接收输入和前一个时间步的隐藏状态,并输出一个新的隐藏状态。输入维度为1,输出维度为10。batch_first=True表示输入数据的形状为(batch_size, sequence_length, input_size)。nn.LSTM(1, 10, batch_first=True): 为了解决RNN的长期依赖问题,LSTM引入了一个记忆单元(cell state)和三个门:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。nn.GRU(1, 10, batch_first=True): GRU是一种介于RNN和LSTM之间的结构,相较于LSTM更简单。它合并了遗忘门和输入门,仅保留了一个更新门(update gate)和一个重置门(reset gate)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Model (nn.Module): def __init__ (self ): super ().__init__() self.rnn = nn.RNN(1 , 10 , batch_first=True ) self.lstm = nn.LSTM(1 , 10 , batch_first=True ) self.gru = nn.GRU(1 , 10 , batch_first=True ) self.fc1 = nn.Linear(10 , 1 ) def forward (self, x, hidden ): output, hidden = self.lstm(x, hidden) output = self.fc1(output[:, -1 , :]) return output
训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 net = Model() loss_fn = nn.MSELoss() opt = torch.optim.Adam(net.parameters(), lr=0.001 ) h0 = torch.zeros(1 , 5 , 10 ) c0 = torch.zeros(1 , 5 , 10 ) for epoch in range (500 ): for i, data in enumerate (train_loader): x, y = data x = x.view(-1 , 10 , 1 ) pred = net(x, (h0, c0)) loss = loss_fn(pred, y) opt.zero_grad() loss.backward() opt.step() if epoch % 50 == 0 : print ('epoch: {}, loss: {:.5f}' .format (epoch, loss.item()))
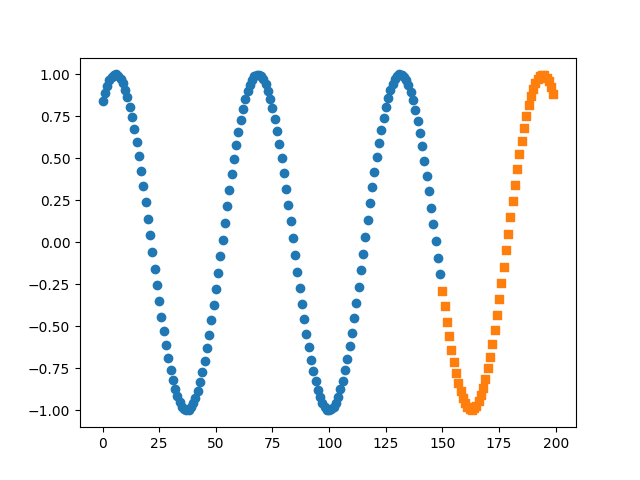
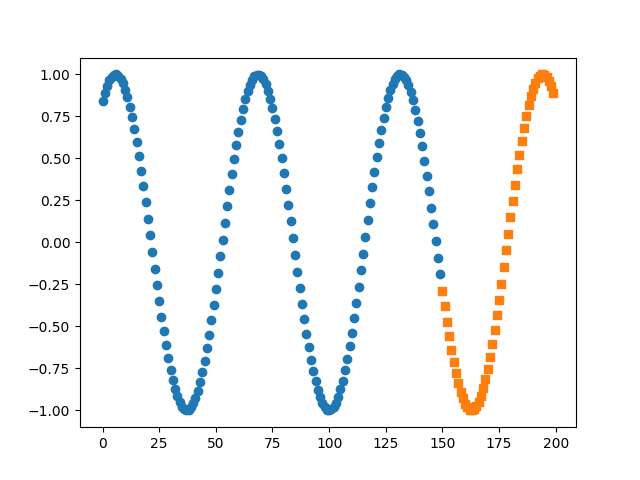
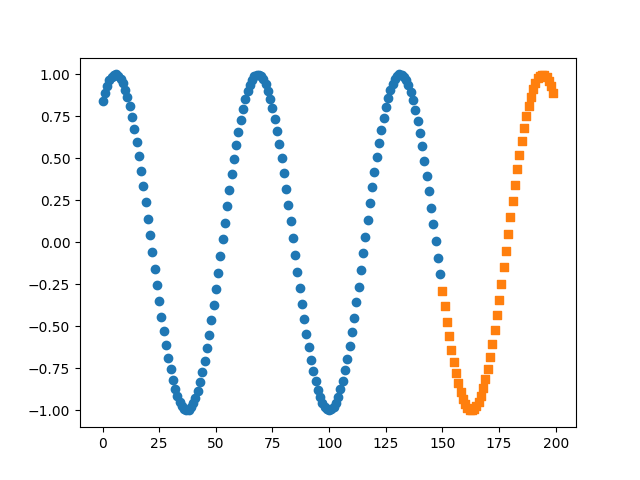
测试 1 2 3 4 5 6 7 8 9 10 11 12 13 preds = [] for i, data in enumerate (test_loader): x, y = data x = x.view(-1 , 10 , 1 ) hidden = torch.zeros(1 , 5 , 10 ) pred = net(x, (h0, c0)) preds.append(pred.data.numpy()) print (y.view(1 , -1 ).data) print (pred.view(1 , -1 ).data, '\n' ) plt.scatter(range (len (train_y)), train_y.data.numpy(), marker='o' ) plt.scatter(range (150 , 200 ), preds, marker='s' ) plt.show()98191
输出: RNN 训练期间损失输出: 1 2 3 4 5 6 7 8 9 10 epoch: 0, loss: 0.57561 epoch: 50, loss: 0.00049 epoch: 100, loss: 0.00011 epoch: 150, loss: 0.00001 epoch: 200, loss: 0.00004 epoch: 250, loss: 0.00001 epoch: 300, loss: 0.00000 epoch: 350, loss: 0.00001 epoch: 400, loss: 0.00000 epoch: 450, loss: 0.00000
测试结果对比:
tensor([[-0.2879, -0.3821, -0.4724, -0.5581, -0.6381]])
tensor([[-0.2888, -0.3836, -0.4745, -0.5604, -0.6403]])
tensor([[-0.7118, -0.7784, -0.8371, -0.8876, -0.9291]])
tensor([[-0.7133, -0.7791, -0.8372, -0.8873, -0.9288]])
tensor([[-0.9614, -0.9841, -0.9969, -0.9998, -0.9927]])
tensor([[-0.9611, -0.9838, -0.9966, -0.9994, -0.9925]])
tensor([[-0.9756, -0.9488, -0.9126, -0.8672, -0.8132]])
tensor([[-0.9758, -0.9496, -0.9139, -0.8689, -0.8150]])
tensor([[-0.7510, -0.6813, -0.6048, -0.5223, -0.4346]])
tensor([[-0.7527, -0.6825, -0.6053, -0.5220, -0.4338]])
tensor([[-0.3425, -0.2470, -0.1490, -0.0495, 0.0504]])
tensor([[-0.3415, -0.2462, -0.1488, -0.0499, 0.0496]])
tensor([[0.1499, 0.2478, 0.3433, 0.4354, 0.5231]])
tensor([[0.1489, 0.2470, 0.3428, 0.4352, 0.5231]])
tensor([[0.6055, 0.6820, 0.7516, 0.8137, 0.8676]])
tensor([[0.6056, 0.6818, 0.7510, 0.8128, 0.8665]])
tensor([[0.9129, 0.9491, 0.9758, 0.9928, 0.9998]])
tensor([[0.9117, 0.9476, 0.9740, 0.9907, 0.9975]])
tensor([[0.9968, 0.9839, 0.9612, 0.9288, 0.8872]])
tensor([[0.9946, 0.9818, 0.9595, 0.9276, 0.8862]])
GRU 训练期间损失输出: 1 2 3 4 5 6 7 8 9 10 epoch: 0, loss: 0.44557 epoch: 50, loss: 0.00044 epoch: 100, loss: 0.00007 epoch: 150, loss: 0.00003 epoch: 200, loss: 0.00001 epoch: 250, loss: 0.00001 epoch: 300, loss: 0.00000 epoch: 350, loss: 0.00003 epoch: 400, loss: 0.00001 epoch: 450, loss: 0.00000
测试结果对比:
tensor([[-0.2879, -0.3821, -0.4724, -0.5581, -0.6381]])
tensor([[-0.2867, -0.3809, -0.4715, -0.5576, -0.6382]])
tensor([[-0.7118, -0.7784, -0.8371, -0.8876, -0.9291]])
tensor([[-0.7124, -0.7792, -0.8379, -0.8880, -0.9290]])
tensor([[-0.9614, -0.9841, -0.9969, -0.9998, -0.9927]])
tensor([[-0.9606, -0.9826, -0.9949, -0.9976, -0.9906]])
tensor([[-0.9756, -0.9488, -0.9126, -0.8672, -0.8132]])
tensor([[-0.9739, -0.9477, -0.9121, -0.8673, -0.8137]])
tensor([[-0.7510, -0.6813, -0.6048, -0.5223, -0.4346]])
tensor([[-0.7516, -0.6818, -0.6048, -0.5217, -0.4333]])
tensor([[-0.3425, -0.2470, -0.1490, -0.0495, 0.0504]])
tensor([[-0.3407, -0.2450, -0.1471, -0.0481, 0.0513]])
tensor([[0.1499, 0.2478, 0.3433, 0.4354, 0.5231]])
tensor([[0.1501, 0.2475, 0.3427, 0.4348, 0.5228]])
tensor([[0.6055, 0.6820, 0.7516, 0.8137, 0.8676]])
tensor([[0.6058, 0.6829, 0.7530, 0.8153, 0.8692]])
tensor([[0.9129, 0.9491, 0.9758, 0.9928, 0.9998]])
tensor([[0.9142, 0.9499, 0.9760, 0.9924, 0.9991]])
tensor([[0.9968, 0.9839, 0.9612, 0.9288, 0.8872]])
tensor([[0.9960, 0.9832, 0.9608, 0.9289, 0.8877]])
LSTM 训练期间损失输出: 1 2 3 4 5 6 7 8 9 10 epoch: 0, loss: 0.65284 epoch: 50, loss: 0.00016 epoch: 100, loss: 0.00011 epoch: 150, loss: 0.00001 epoch: 200, loss: 0.00000 epoch: 250, loss: 0.00000 epoch: 300, loss: 0.00000 epoch: 350, loss: 0.00000 epoch: 400, loss: 0.00001 epoch: 450, loss: 0.00004
测试结果对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 tensor([[-0.2879, -0.3821, -0.4724, -0.5581, -0.6381]]) tensor([[-0.2881, -0.3823, -0.4726, -0.5581, -0.6380]]) tensor([[-0.7118, -0.7784, -0.8371, -0.8876, -0.9291]]) tensor([[-0.7115, -0.7779, -0.8367, -0.8874, -0.9293]]) tensor([[-0.9614, -0.9841, -0.9969, -0.9998, -0.9927]]) tensor([[-0.9620, -0.9850, -0.9978, -1.0005, -0.9930]]) tensor([[-0.9756, -0.9488, -0.9126, -0.8672, -0.8132]]) tensor([[-0.9759, -0.9493, -0.9137, -0.8691, -0.8157]]) tensor([[-0.7510, -0.6813, -0.6048, -0.5223, -0.4346]]) tensor([[-0.7539, -0.6841, -0.6072, -0.5242, -0.4361]]) tensor([[-0.3425, -0.2470, -0.1490, -0.0495, 0.0504]]) tensor([[-0.3441, -0.2489, -0.1514, -0.0523, 0.0475]]) tensor([[0.1499, 0.2478, 0.3433, 0.4354, 0.5231]]) tensor([[0.1470, 0.2451, 0.3408, 0.4329, 0.5204]]) tensor([[0.6055, 0.6820, 0.7516, 0.8137, 0.8676]]) tensor([[0.6025, 0.6784, 0.7476, 0.8094, 0.8634]]) tensor([[0.9129, 0.9491, 0.9758, 0.9928, 0.9998]]) tensor([[0.9090, 0.9456, 0.9726, 0.9896, 0.9963]]) tensor([[0.9968, 0.9839, 0.9612, 0.9288, 0.8872]]) tensor([[0.9929, 0.9797, 0.9569, 0.9249, 0.8838]])